Nó de LLM
O nó LLM (Large Language Model) é o motor de inteligência do seu fluxo de trabalho. É através dele que você processa linguagem natural, toma decisões complexas, analisa dados não estruturados e gera conteúdo criativo utilizando modelos de ponta.

Configuração
Ao clicar no nó, o painel lateral oferece controle total sobre o comportamento da IA. Abaixo detalhamos cada seção de configuração.
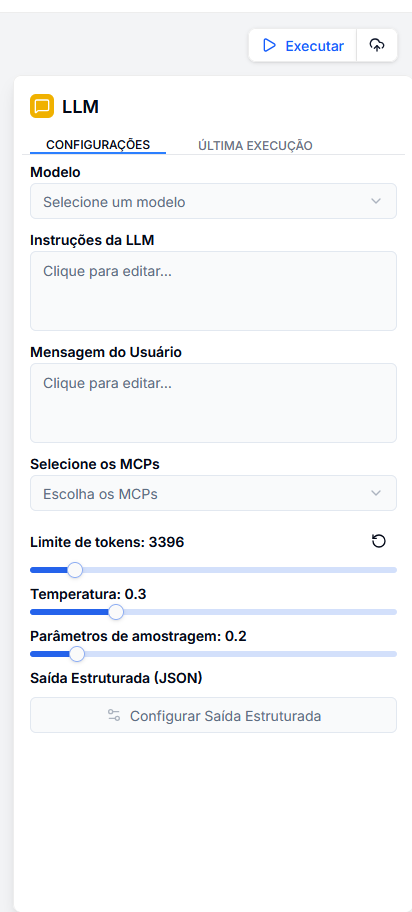
1. Seleção de Modelo
Aqui no bloco de LLM é possível selecionar todos modelos que foram adicionados ao seu projeto.
Nota: Ao trocar de modelo, o sistema ajusta automaticamente o limite máximo de tokens suportado por aquele modelo específico.
2. Prompts e Instruções
É aqui que você define a personalidade e a tarefa da IA.
Instruções da LLM (System Prompt)
Define os parâmetros operacionais, tom de voz e limitações do agente. Pense nisso como "quem a IA é".
Você é um analista financeiro sênior.
Sempre forneça explicações claras e cite fontes quando possível.
Ao responder sobre investimentos, inclua avisos de risco.
Mensagem do Usuário (User Prompt)
Representa a entrada de dados para processamento. Pode ser texto estático ou dinâmico vindo de outros nós.
Analise o sentimento da seguinte mensagem de suporte:
Mensagem: "{{ entrada.mensagem_cliente }}"
Histórico: "{{ banco_vetorial.contexto }}"
3. Ferramentas (MCPs)
Estenda as capacidades da IA conectando-a ao mundo externo via MCP (Model Context Protocol). Você pode selecionar até 5 servidores simultâneos para dar à IA habilidades como:
- Comunicação: Enviar mensagens no Slack, WhatsApp ou E-mail.
- Dados: Consultar bancos de dados (Postgres, Supabase) ou planilhas.
- Web: Realizar pesquisas no Google ou ler páginas web em tempo real.
Quando ativado, a IA decide autonomamente quando usar uma ferramenta com base na pergunta do usuário.
4. Parâmetros de Controle
Ajuste a criatividade e o tamanho da resposta:
| Parâmetro | Faixa Recomendada | Descrição |
|---|---|---|
| Baixa | 0.0 - 0.3 | Determinístico e focado. Ideal para extração de dados, classificação e tarefas factuais. |
| Média | 0.3 - 0.7 | Equilibrado. Bom para respostas gerais de chat e assistentes virtuais. |
| Alta | 0.7 - 1.0 | Criativo e variado. Ideal para brainstorming, escrita criativa e geração de ideias. |
- Top P: Uma alternativa à temperatura para controlar a diversidade do vocabulário (recomendamos manter o padrão se alterar a temperatura).
- Limite de Tokens: Define o tamanho máximo da resposta gerada para controlar custos e verbosidade.
Saída Estruturada (JSON)
Para automações confiáveis, texto livre nem sempre é útil. O parâmetro Saída Estruturada força a IA a responder seguindo um esquema JSON estrito.
Ao clicar em Configurar Saída Estruturada, você pode definir visualmente os campos ou escrever o schema JSON. Ao editar um, o outro será atualizado automaticamente desde que sejam preenchidos no formato esperado.
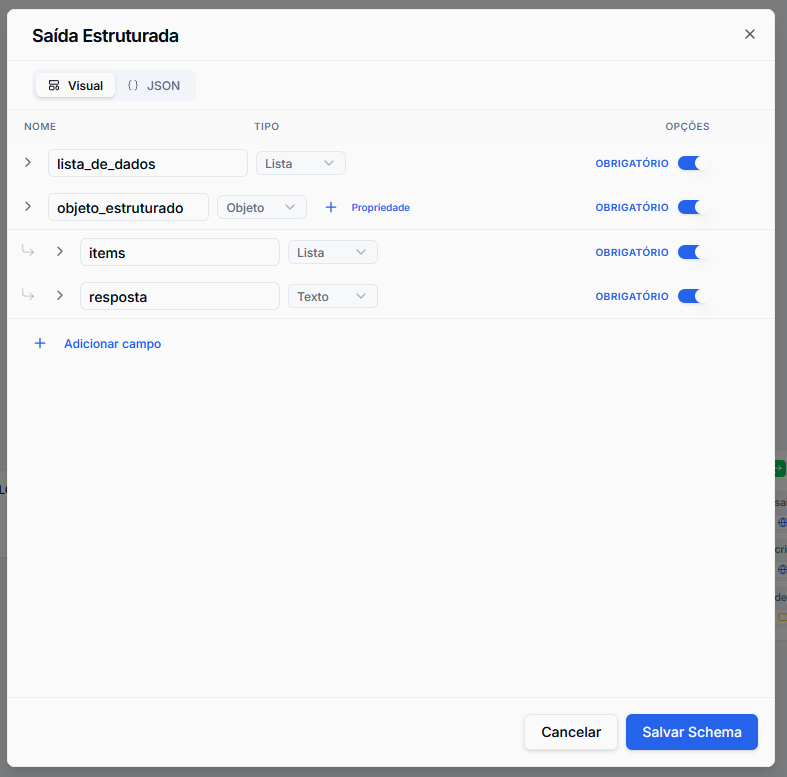
Isso garante que o próximo nó do seu fluxo (como uma condicional ou integração HTTP) receba dados limpos e prontos para uso.
Variáveis de Saída
Após a execução, este nó disponibiliza as seguintes variáveis para uso no fluxo:
completion.content: O texto principal da resposta ou o JSON gerado.completion.usage: Estatísticas de uso de tokens (prompt, completion, total).tool_calls: Detalhes técnicos se a IA utilizou alguma ferramenta MCP.
Casos de Uso Práticos
Veja como configurar o nó de LLM para diferentes cenários:
Automação de Suporte (RAG)
- Instrução: "Você é um assistente de suporte útil baseada na Base de Conhecimento fornecida."
- Usuário: "Responda à pergunta:
{{ entrada.pergunta }}baseado no contexto:{{ busca_vetorial.chunks }}" - Temperatura: 0.2 (Para evitar alucinações).
Analista de Dados
- Instrução: "Extraia as entidades principais do texto."
- Usuário: "Texto:
{{ extrator_arquivo.texto }}" - Saída Estruturada: Ativa (definindo campos como
nomes,datas,valores).
Criador de Conteúdo
- Instrução: "Você é um redator criativo de marketing."
- Usuário: "Crie 5 variações de títulos para um post sobre:
{{ entrada.tema }}" - Temperatura: 0.9 (Para máxima criatividade).
Boas Práticas
- Seja específico no System Prompt: Quanto mais claras as regras e limitações, melhor o desempenho da IA.
- Use Saída Estruturada para Integrações: Se o dado vai para uma API ou Banco de Dados, nunca confie em texto livre.
- Cuidado com o Contexto: Passar documentos inteiros no prompt pode ser caro e lento. Use nós de RAG (Busca Vetorial) para filtrar apenas o que importa antes de enviar para a LLM.